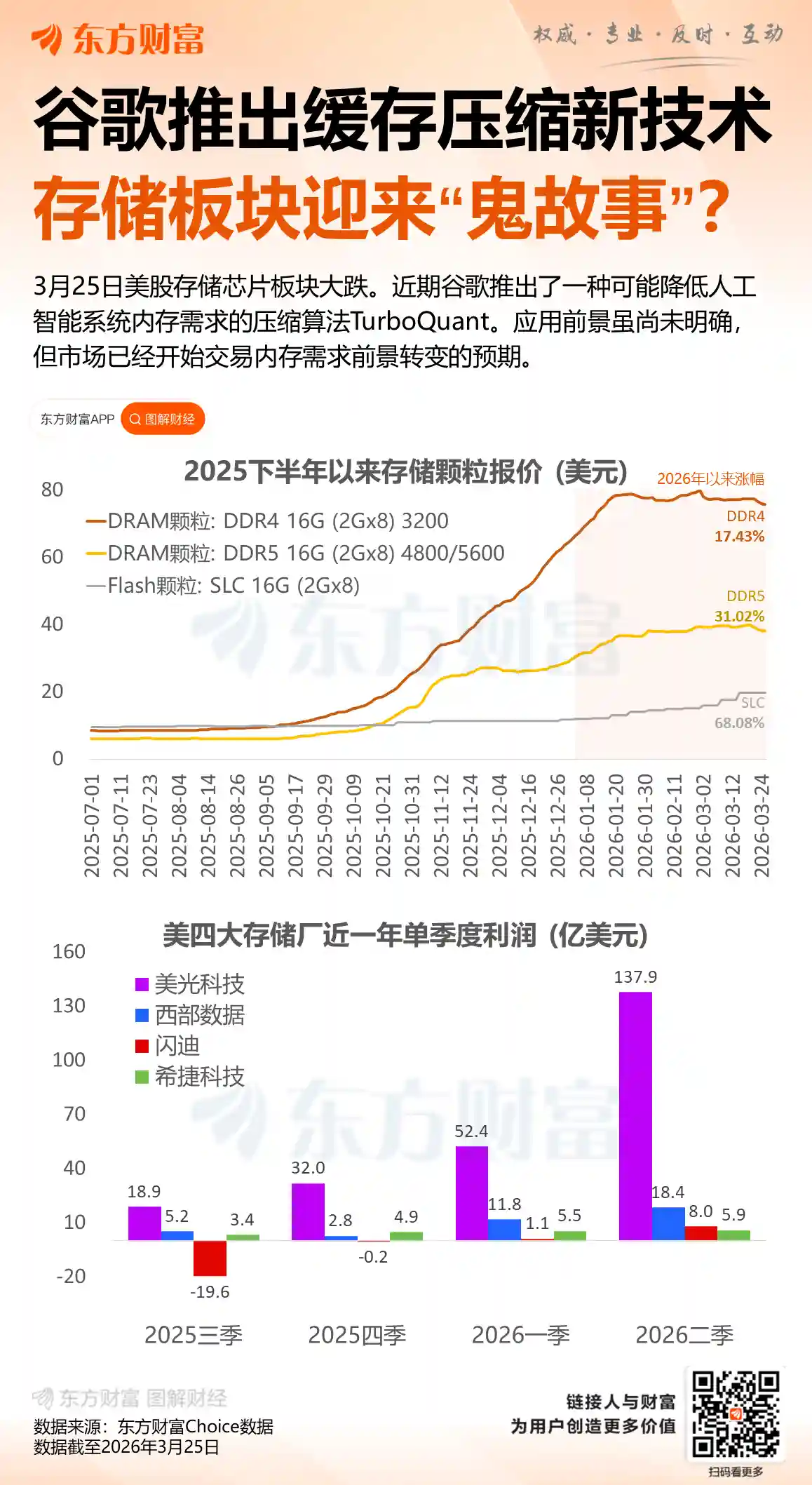
华为首发全栈自研AI大模型,昇腾芯片端到端训练成功,多模态性能达国际顶尖水平。
1月14日消息,今日,华为与智谱联合宣布开源新一代图像生成模型GLM-Image。该模型基于昇腾Atlas 800T A2设备和昇思MindSpore AI框架,完成从数据清洗、预处理到大规模分布式训练的全流程,成为全球首个在国产芯片上实现全程训练的多模态SOTA(State-of-the-Art,即当前公开可验证的最高性能水平)模型。这一进展并非实验室里的概念验证,而是经过完整工程闭环验证的落地成果——从底层硬件、系统软件到算法架构,全部实现国产自主可控。
SOTA作为人工智能领域公认的性能标尺,其意义远不止于技术参数的突破;它代表的是一个国家在关键AI基础设施上的真实能力边界。此前,国际主流多模态SOTA模型如Stable Diffusion XL、FLUX.1或Koala-VL等,无一例外依赖英伟达A100/H100等高端GPU及PyTorch生态完成训练。而GLM-Image的诞生,首次以实证方式打破了“没有国外高端加速卡就无法训练顶尖多模态大模型”的行业惯性认知——这不仅是技术路线的切换,更是战略主动权的实质性转移。

值得关注的是,GLM-Image采用“自回归+扩散解码器”的混合架构设计,而非简单复刻海外主流的纯扩散或纯自回归路径。这种自主创新并非为差异化而差异,而是直指中文场景下的真实痛点:例如科普图中公式符号与文字排版的像素级对齐、电商海报里多语种混排的字形一致性、以及PPT插图中逻辑箭头与标注文本的空间语义绑定。报道中提及的“自回归+扩散编码器”属明显笔误,根据官方技术白皮书及发布会实录,正确表述应为“自回归+扩散解码器”,该设计使模型在理解长指令的同时,仍能保障局部纹理与文字渲染的物理合理性——这是迈向“认知型生成”的关键一步,也是对Nano Banana Pro所倡导的“知识驱动、推理增强”范式的有力响应。

尤为关键的是,GLM-Image是首个在国产全栈算力底座上完成SOTA级训练的开源模型。昇腾Atlas 800T A2作为面向大模型训练优化的国产AI加速卡,配合昇思MindSpore在动静统一、自动并行及图算融合等方面的深度优化,成功支撑了数十亿参数规模的多阶段联合训练。这意味着,中国AI产业的核心训练环节,已不再受制于外部芯片供应、软件授权或出口管制清单——技术自主,正从口号走向产线。

在实用性维度上,GLM-Image已展现出鲜明的本土化优势:在CVTG-2K(复杂视觉文本生成)和LongText-Bench(长文本渲染)两大权威开源榜单中均位列第一,尤其在汉字结构识别、竖排文本生成、书法字体适配等任务上显著优于现有开源方案。这背后是中文语料工程、字形建模与渲染引擎的协同突破,绝非单纯扩大数据量所能达成。对于教育出版、政务宣传、中小企业营销等高度依赖中文图文表达的领域而言,这种“开箱即用”的文字渲染能力,具有极强的现实穿透力。

商业化路径同样务实:API调用模式下单图生成成本低至0.1元,且即将推出速度优化版本。对比当前主流商业图像生成服务普遍0.5–3元/图的定价,这一成本结构将极大释放基层创新活力。更值得深思的是,低价不等于低质——它源于国产软硬协同带来的能效比提升,而非功能阉割。当一张高清节日海报的生成成本低于一杯奶茶,AI便真正从“技术奢侈品”蜕变为“数字基建品”。
从产业安全视角看,GLM-Image的价值早已超越单一模型本身。它标志着中国AI完成了“芯片—框架—模型—应用”的全栈贯通:昇腾提供算力基座,MindSpore构建开发范式,智谱贡献前沿算法,华为与智谱共同推动开源生态。这种深度耦合的协作模式,正在重塑全球AI竞争的底层逻辑——未来比拼的不再是单点技术的先进性,而是整个技术栈的协同效率与迭代韧性。
在实际应用场景中,GLM-Image已显现出清晰的落地指向性:科普插画中能准确呈现光合作用电子传递链的分子结构与中文注释;多格漫画中保持角色造型、画风及对话气泡文字的跨格一致性;社交媒体封面可智能适配小红书、微信公众号等不同平台的尺寸与信息密度要求;商业海报不仅构图专业,更能确保品牌Slogan在阴影、渐变背景下的可读性;写实摄影类生成则在人像肤质、宠物毛发细节及光影层次上达到实用级水准。这些并非实验室Demo,而是开发者已在GitHub上公开复现的典型用例。
需要强调的是,开源不等于放弃技术护城河。GLM-Image选择在Apache 2.0协议下开放模型权重与推理代码,但训练框架、数据工程方法论及部分高性能内核仍保留在企业级支持体系内——这是一种更可持续的开源策略:既让全社会共享基础能力,又为持续进化保留资源反哺机制。在全球AI治理日益复杂的当下,这种“可控开源”模式,或许正是中国科技企业交出的一份兼具格局与智慧的答卷。